Benchmarketing and the Texas Sharpshooter
Series: The history of modern technical propaganda
25th of February, 2024
In today’s complex world, programming and statistics are evolving into fundamental elements of basic literacy. These skills will become even more important as the gap between surface knowledge and deep knowledge of advanced technical topics like AI and quantum increases exponentially. Without a baseline knowledge of programming and statistics, people will become increasingly vulnerable to manipulation on a host of important topics that are bound to be debated over the coming years, from AI ethics, to the government regulation of AI technologies, to the legality of AI models claiming fair use under copyright law when training on copyrighted materials.
If we agree that the opportunity for technical manipulation will only increase over time, it’s worth asking what level of manipulation does it take to fit the definition of propaganda?
To help answer this question, let’s review two modern examples of potential technical propaganda that are relatively straightforward to cover: benchmarketing and fauxpen license shifting. I encourage you to decide for yourself if these examples are propaganda, marketing spin, or simple technical misunderstandings. Discussing more straightforward examples of potential propaganda in a modern context might help us to tackle much more sophisticated forms of technical propaganda that will arise over the coming years.
Let’s start with a prime example of what I personally consider technical propaganda in the modern context, the practice of benchmarketing.
Benchmarketing
The Texas Sharpshooter fallacy originates from a joke about a Texan who “indiscriminately shoots at the side of a barn and then paints a target around the tightest cluster of hits to proclaim his marksmanship”. This logical fallacy occurs when someone selectively focuses on a subset of data from a larger set, ignoring the rest, to support a specific conclusion.1
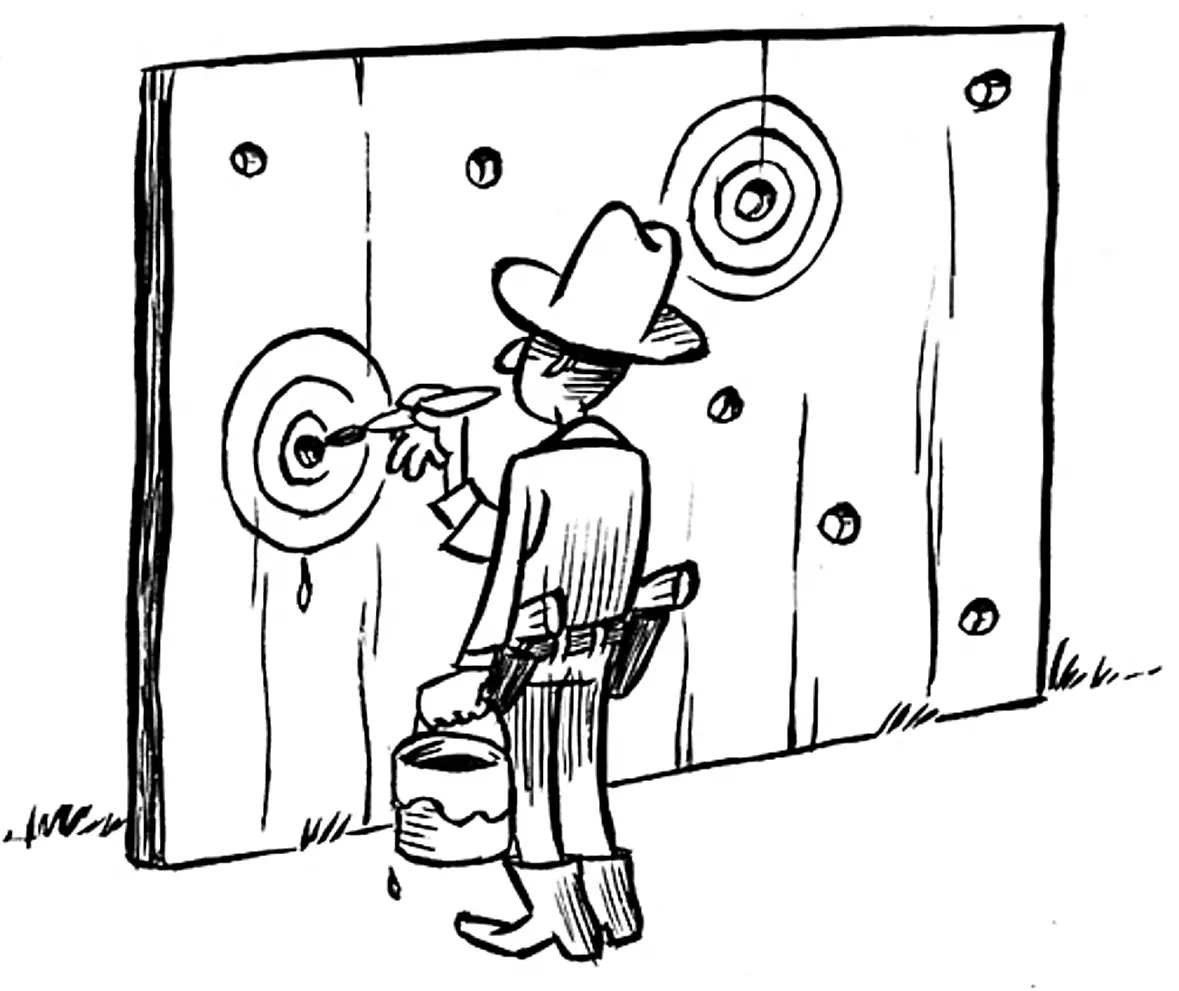
“There are three types of lies: lies, damned lies, and statistics.” – Mark Twain
Twain popularized the above quote, reflecting his general skepticism towards the manipulation of people with math, bullshit, and mathematical bullshit. There’s a level of mathematical literacy needed to discern even small nuances in a statistical argument. Consider the measurement “average latency.” A low average latency sounds good, right? But averaging latency actually means almost nothing, because a real user’s experience with a software product is dependent on the outliers, typically represented as percentiles (like p90, p95, etc). Anyone without an understanding of statistics, like averages, means, and percentiles, can be duped into thinking that average latency means something. While development and SRE teams may spot these types of statistical nuances from a mile away, hands-off executives with purchasing decision power might not.
Within the realm of product marketing, particularly in the startup scene, the Texas Sharpshooter fallacy isn’t simply a statistical error – it’s often an embraced strategy. Marketing narratives are typically designed with a specific aim, like claiming “our product is faster and more reliable than yours.” In less-principled marketing teams, employees and consultants are then directed to find data to support the narrative, rather than the other way around. Any data uncovered that doesn’t fit the narrative is conveniently ignored.
The Texas Sharpshooter and Twain’s quote point out a shared idea: when a selective attention to data is deliberate, with the aim of shaping public perception or outmaneuvering competitors, it crosses an ethical boundary. When the end goal is to have a marketed opinion accepted as an established fact, often to the detriment of competing products, it’s propaganda. Let’s start to call this out for what it is.2
So, what is benchmarketing, exactly?
- Benchmarketing is the marketing practice of highlighting specific performance benchmarks to showcase a product favorably, often by focusing excessively on positive data points while ignoring or omitting less favorable ones.
- Another characteristic of benchmarketing is that it compares one project against another project to help amplify the distorted presentation of data, for instance, by over-indexing on a single feature of one project to make the entire project look superior to another competing project.
- Benchmarketing also tends to conflate specific measurements like latency and throughput with the broader concept of performance, by conveniently omitting important tradeoffs, or even worse, gaming the measurements.
Benchmarketing not only distorts market perceptions, but distorts market outcomes. Why? Increasingly, free and open source software (FOSS) projects are finding themselves the target of benchmarketing campaigns by commercial open source software (COSS) companies. In my opinion this will only get worse as we enter a tougher macroeconomic climate. The industry should expect more benchmarketing as the battle for every dollar of revenue intensifies. FOSS projects will be an easy target for unethical COSS marketing teams who must grow market share by any means necessary.
Now, let’s delve into the origins of “benchmarketing,” explore its evolution, and discuss ways to prevent both the production of and susceptibility to this type of marketing.
2017 – Databricks Runtime vs Apache Kafka and Apache Flink
In 2017, Databricks promoted a series of benchmarks showing a substantial performance advantage between Apache Spark – which is at the heart of the Databricks Runtime project – over Apache Flink and Apache Kafka Streams (KStreams). They published a report called Benchmarking Structured Streaming on Databricks Runtime Against State-of-the-Art Streaming Systems, which summarized the performance of various tests run using the Yahoo Streaming Benchmark, along with Databricks Notebooks.3
Their initial analysis showed that Spark achieved higher throughput compared to the other systems compared, with the final summary that Spark reached over 4x the throughput of its competitors.
What’s the issue?
Upon scrutiny, Databricks’ claims fell apart after technologists from Ververica found non-trivial issues with the analysis. They were the first to call the report purposefully unethical, against the ethos of open source, and distracting to FOSS by diverting energy into refuting the report rather than enhancing the projects. Ververica’s rebuttal, The Curious Case of the Broken Benchmark: Revisiting Apache Flink® vs. Databricks Runtime, is the first time I came across the term benchmarketing after a colleague pointed me towards it.4
Ververica identified two main issues with the Databricks benchmark: a bug in the Flink data generator code that was actually written by Databricks themselves, and an incorrect Flink configuration setting regarding object reuse. After addressing these issues, Ververica found that Flink significantly outperformed Spark in throughput for these specific tests. This led to a much more transparent understanding of the benchmark’s results:
- Spark achieved throughput of 2.5 million records per second (in line with what Databricks reported in their post)
- Flink achieved throughput of 4 million records per second (significantly better performance than originally reported)
The Ververica rebuttal underscores an important aspect of benchmarking in technology: the specificity and limitations of the benchmark itself. A narrow benchmark, such as one focusing solely on word counting, with particular configurations and in a specific deployment environment, is unlikely to represent a range of real-world workloads.
This highlights the crucial need for context in any benchmarking exercise: all benchmarks tell a story, so it’s essential for those conducting benchmarks to be transparent about the story they aim to tell with the results. This should include the full scope and intention of their tests, such as specific workloads they plan to highlight, which helps to ensure that the story being told is relevant and accurate. Without transparency, we quickly slide down the slippery slope of technical propaganda.
Why was this particular incidence of benchmarketing harmful to the open source community? Apache Spark, Apache Flink, and Apache Kafka are all free and open source projects (FOSS), governed by Apache, and collaboratively developed by a group of technologists who devote a great deal of time and effort to furthering these important projects. When a well-funded vendor conducts biased marketing activities disguised as unbiased research, it harms open source by forcing the FOSS developer community to spend time refuting benchmarks instead of innovating. Remember, propaganda always disguises itself as education, and refuting education is hard work.
There comes a time in the life of every stream processing project when its contributors must decide, “Are we here to solve previously unsolvable production problems for our users, or are we here to write blog posts about benchmarks?” – Stephan Ewen 5
There are many other examples of benchmarketing in the wild, and it wouldn’t take long for you to find some on your own. Rather than run through the entire catalog of benchmarketing examples, let’s instead explore some suggestions on how to produce a benchmark ethically. There’s nothing inherently negative about a benchmark, and they can be conducted without forcing developers to compromise their integrity, or distract the FOSS community into working on benchmarketing rebuttals rather than solving unsolved technical problems.
How to produce an ethical benchmark
Instead of creating new guidelines and recommendations from scratch, I’ll borrow liberally from Ververica’s rebuttal. I believe their insights are spot-on, so there’s no need to change what already works well. The following is a blend of Ververica’s original suggestions with my own thoughts sprinkled throughout.
Benchmarks should be carried out by neutral third parties, and all stakeholders should be offered a chance to review and respond. Neutral third parties should craft and execute benchmarks on behalf of the community, and give all stakeholders, including open source communities, a voice in the review process. A neutral and inclusive approach to benchmarks helps to mitigate bias, enhances the legitimacy of the results, and separates real benchmarking initiatives from propaganda. For organizations with an Open Source Program Office (OSPO), tasking the OSPO with oversight of COSS-driven benchmarking initiatives – with minimal corporate influence along the way – can help to further guarantee accuracy and ethical conduct. There’s no way to eliminate bias, but there are many ways to reduce the opportunity for bias.
Ensure benchmarks represent real workloads, and be honest about gaps. To ensure benchmarks are meaningful and fair, they must accurately represent real-world workloads and acknowledge any limitations. Benchmarks that selectively focus on specific features of a project to support a premeditated narrative is likely leading toward benchmarketing propaganda. This is especially true for complex systems like database management systems and streaming platforms, which have diverse capabilities that benchmarks often fail to fully encompass. Claims like “project X is 150% faster than project Y” is unethical unless all features of the projects are thoroughly compared, which is rare due to potential compatibility differences between projects, and the sheer complexity of such a comprehensive benchmark comparison. Transparently reporting on what exactly has been tested and acknowledging gaps is essential for benchmarks to be trustworthy and valuable.
Living benchmarks are better than static benchmarks. Software changes frequently, and one-off benchmarks may only be accurate for a short period of time. In my opinion, Clickhouse has one of the best open source benchmark portals I’ve come across at https://benchmark.clickhouse.com, as it not only covers a wide array of configuration, hardware, and cloud variants, but also a ton of different query types. Enabling end users to compare Clickhouse against a wide array of alternatives, without prejudicing the evaluation with some kind of pre-canned narrative, puts the focus solely on the numbers. The story is up to the person viewing the numbers. Treating benchmarks as evolving, iterative projects instead of one-off static reports further reduces bias and maintains relevance.
Publish a detailed methodology out in the open and accept contributions. To further highlight ClickHouse, they have open sourced their benchmarking framework, ClickBench. Excellent materials are available out in the open about their testing methodology, including key factors such as reproducability, realism, and limitations. Not only that, but they accept contributions to their test harnesses, which is valuable as ClickBench is a living and breathing benchmark rather than a static analysis.6
Only refute benchmarks if requested by the open source community. In the event of a benchmarking report being released by a vendor, there will be a knee jerk reaction for other COSS vendors to respond forcefully. When this pressure seeps into FOSS development and maintenance efforts, it leads to a very distracting cycle of nonsense that adds no real value to any of the projects involved. Let the developers and maintainers of targeted projects decide whether or not to respond. Ververica’s approach was solid, because rather than responding right away, they only responded after being pressed by the Apache Flink and Apache Kafka communities. This showed a high level of respect for the people in the trenches.
To highlight the last point, below is a quote that offers more context around Ververica’s decision to respond. By holding off on a response until the community requested help, this helped to preserve the focus of contributors to Apache Spark, Apache Flink, and Apache Kafka. The first way to ensure an ethical approach to benchmarks and rebuttals is for the open source community to drive such initiatives, not whatever COSS marketing team has the deepest pockets to counter benchmarketing with even more benchmarketing.
“We delayed investigating the benchmark results because we quite strongly believe that putting time and resources into an increasingly irrelevant benchmark is of no benefit to users. But we heard feedback from the community that input from a Flink perspective would be helpful, so we decided to take a closer look.” – Aljoscha Krettek, The Curious Case of the Broken Benchmark
By following general common sense guidelines around how to produce an ethical and valuable benchmark analysis, the community can focus on benchmark results that really matter: genuine explorations of new ideas and opportunities to improve the performance of free and open source software.
Continue reading
It’s your call whether the Databricks analysis constitutes technical propaganda, or was an honest analytical mistake. However, such controversies are completely avoidable by following the outlined recommendations for ethical benchmarking. It’s important to remember that Databricks has contributed significantly to the FOSS community through their technical innovations, which makes this all the more important of an example for us to learn from.
Including the open source community into benchmarking analysis from the start – and following the other recommendations outlined above – should reduce the chance that such a report will be completely inaccurate and potentially biased from the start. In benchmarketing, like other propaganda, bias begins when the narrative of a report precedes the analysis required for the report, and concludes when rational manipulators force true believers into communicating the results. If nothing else, I hope the key takeaway is that there are simple steps you and your organization can follow to reduce the amount of potential technical propaganda that is flooding the FOSS community.
While benchmarketing is always a borderline case of technical propaganda depending on the context, the next topic we will cover is potentially far more damaging to the open source community: fauxpen license shifting.
What happens when an organization aims to gain all of the public relations benefits that comes with being an ally of an open source, while privately using open source only to further their own agenda? Continue reading to learn more.
Next (part 7 of 7): How to destroy open source with fauxpen license shifting