A successful Event Storming session — as well as a successful software project — demands equal parts art, knowledge, and technical skill. Also, it’s much cheaper to make changes to sticky notes than production code. Learning about your systems by writing code is a very expensive way of understanding and refining the business processes involved.
Nothing in this article requires technical expertise or previous experience with reactive, event-driven systems. Whether you’re a business expert, developer, architect, product owner, or business owner, you should learn a few new techniques that will help you have more success — and fun — collaborating with your team and organization.
What’s a Reactive System?
In a reactive system, interesting business events that occur within an organization can be reacted to in real-time, without the co-ordination costs of centralized control and monolithic system architectures. Your software systems more accurately reflect the true nature of your business.
While “reactive” is classically considered a negative term, in a computer system it’s the ideal flow of control. Rather than needing to explicitly change every piece of a system to make something new happen, the system reacts to events as they occur. Imagine being able to subscribe to any interesting event within your organization and create new systems to react to those events, without having to coordinate with any other teams? That’s the goal.
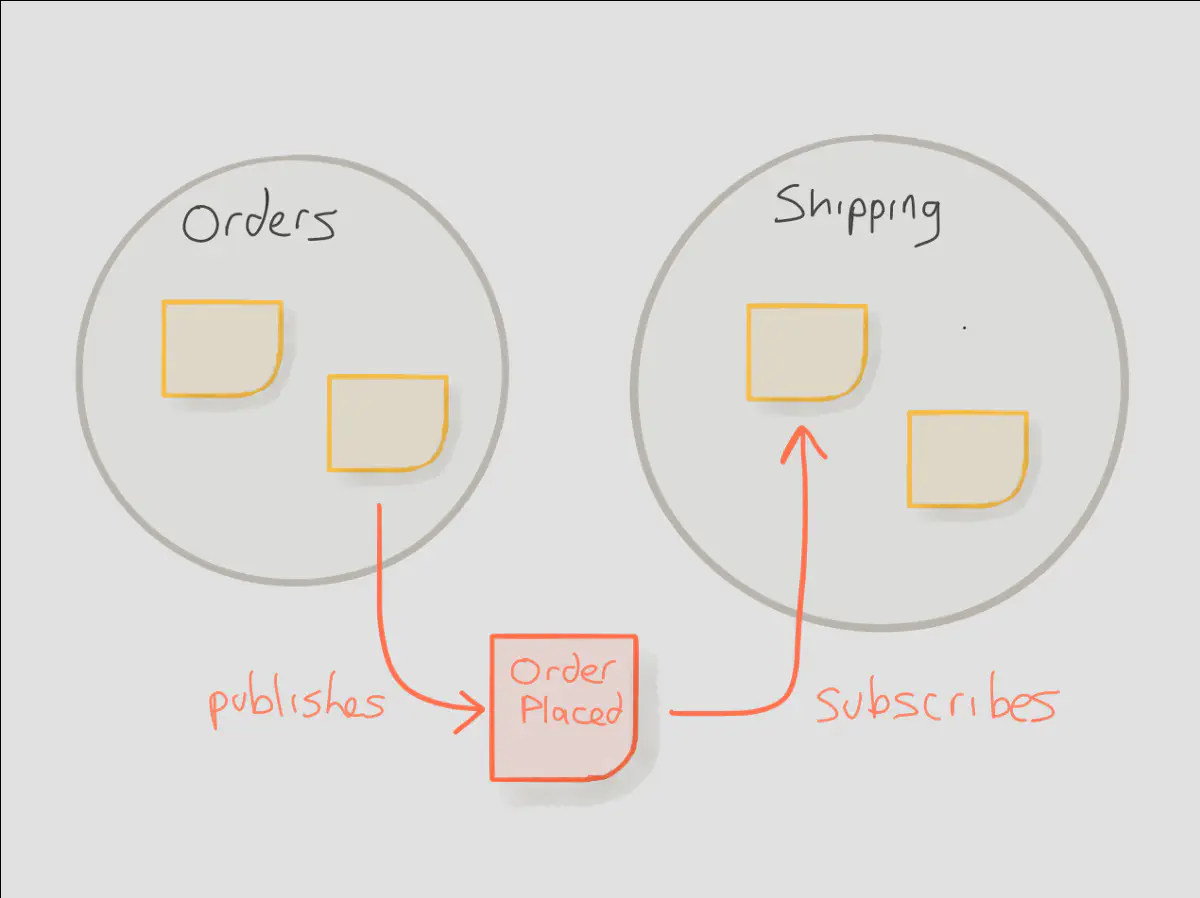
For example, if a Shipping system needs information from an Order system, the Shipping team doesn’t need to request changes to be made by the Order team, they simply subscribe to the relevant events being emitted by the Order system. If interesting events are published by default, it’s very infrequent that teams need to directly coordinate with each other to make important changes in response to business needs.
This is possible because in an event-driven system domain events are published to a journal. Any other system within your organization that has access to the journal can subscribe to published events and react to those events in real-time. The most interesting thing about this method is the simplicity of it; businesses have been operating from journals for centuries. We’re just bringing this method into a modern context.

This level of flexibility has become possible because technology infrastructure has greatly improved over the years, such as the speed and reliability of networks. A decade ago we wouldn’t have been able to justify the latency penalty involved in emitting events over the wire, so we prioritized _locality_and built monolithic applications that could run on single machines.
Now, monolithic systems have grown in such scale and complexity that the coordination cost of many teams working on a single application is too immense to ignore. Improvements in infrastructure has meant the expense of distribution has declined rapidly, so now complex enterprise systems are being rethought of as event-driven systems. This has had a huge impact on how both developers and domain experts think about systems design.

Organizations now have the tools to accomplish the seemingly impossible, such as turning overnight batch processes into real-time systems, transforming static reports generated overnight into mission control dashboards showing every facet of the big-picture in near real time, and so forth. Imagine crafting policies that automatically react to important events in your business on-the-fly? It’s game changing.
Now all we need is a modern technique to help us model such systems.
Event Storming
Event Storming is a form of organizational anthropology; it’s all about discussing the flow of events in your organization and modelling that flow in an easy to understand way. The knowledge gained from an Event Storming session will eventually feed into other modelling techniques to provide structure to the business flows that emerge, but the real value are the conversations involved. You can build a software system from the models, or simply use the knowledge gained from the conversations to better understand and refine the business processes themselves.
The Workshop
Hosting an Event Storming workshop is simple: stakeholders of a system get into a room with an unlimited modelling surface — a giant piece of paper taped to the wall — and put sticky notes all over it. Sounds simple? It is. That’s the joy of Event Storming; it focuses purely on the task at hand, which is understanding your business processes, without all of the ceremony of overly-complex modelling techniques which hinder conversation.

We’ll now introduce the core concepts involved in discussing and modelling event-driven business processes — events, reactions, and commands.
What’s an Event?
First, we’ll begin to think of our business processes purely in terms of _events_and reactions, which is a fancy way of saying “cause-and-effect”.
Things happen. Not all of them are interesting, some may be worth recording but don’t provoke a reaction. The most interesting ones cause a reaction. Many systems need to react to interesting events. Often you need to know why a system reacts in the way it did.
We can restate Martin’s quote as follows:
“Important events cause reactions elsewhere in the system, and it’s often important to understand why those reactions occurred”.
We can take that single statement as our guiding principle and use it to model, architect, and build an event-driven system.
Event Flows
A single event isn’t very exciting, so we need to consider events in term of flow — events over time_._ Orange stickies represent events. To model a business process we simply arrange events from left-to-right in time sequence. That’s it! Sounds simple? It is. That’s the point. There’s no unnecessary ceremony between you, your team, and an interesting discussion that yields results.
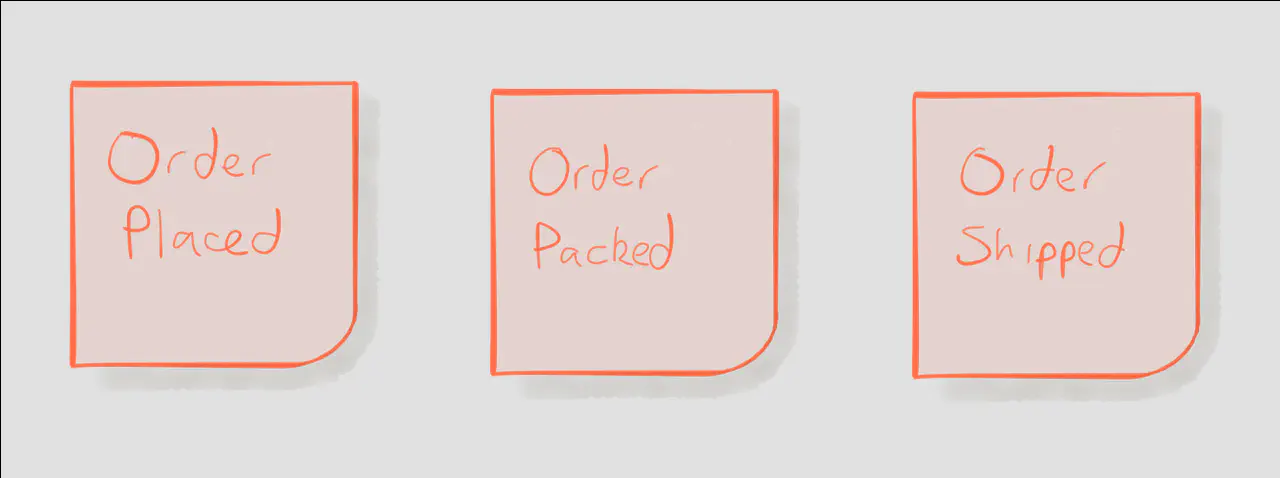
Once we have a linear sequence of events that occurs over time, we need to think about the cause of those events.
What’s a Reaction?
A reaction is something that needs to happen after something else happens. Reactions are best captured in the following statement,
“This happens whenever that happens”.
This is the reaction. That is the event. Whenever is the word that associates an event to a reaction to create a policy.
If you find yourself using the term whenever to describe a sequence of events, you’re speaking in terms of a event-driven system. The order of these statements is less important than the contents of the statement.
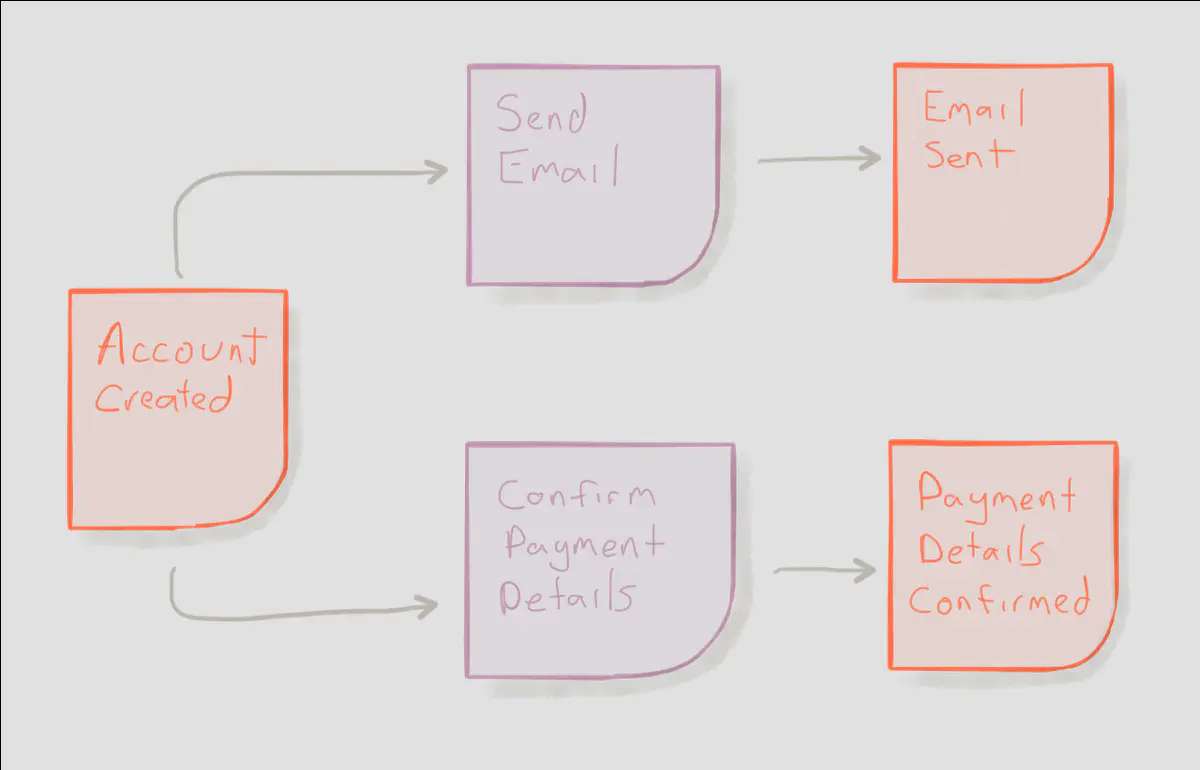
“Whenever a new user account is created we will send her an acknowledgement by email”.
If you read the above statement, the key is in the tense. Events are always past-tense, while reactions are always future-tense. More importantly, we never discuss “now” — we can’t make any assumptions about the current state of a system, because there’s no guarantee that what we intend to happen will actually happen. Mistaken assumptions are the root cause of most failures in computer systems. By modelling only cause-and-effect, we can better decide how to react to anything, because we’re not making false assumptions about outcomes — not only successful outcomes, but also errors and other less-than-ideal events.
What’s a Policy?
The flow of events and reactions together is called a policy — we call this flow a policy because the flow captures core business rules, such as “we need to alert a customer whenever someone logs into their account”.
A single event may cause multiple reactions. It’s also important to consider what happens when things go wrong. This entire flow can be considered an “account creation policy”.
It’s also important to note that a reaction — or an entire policy — doesn’t need to represent a piece of software. For instance, “confirm payment details” may be a manual process that involves an administrator manually verifying wire transfer details. The entire policy may even be implemented as manual processes rules, such as teams phoning each other rather than an automated computer system.Event Storming is an incredibly valuable technique to learn about manual processes in your organization as well as designing new software.
We also see that reactions often cause new events, such as a “fan-out” of reactions; a fan-out is when two or more effects emerge from the other side of whatever caused those effects. Event-driven systems are all about cause-and-effect, so it’s important to capture as many effects as possible. An event that causes a fan-out in this manner is probably worth diving into deeper, perhaps even worthy of its own event storming session.
Another reason to focus on policies is the importance of discussing and designing the process for when things go wrong; for instance, what happens if payment details are not successfully confirmed?
Now that we know events can cause multiple reactions, and those reactions can cause new events. What else can cause events?
- External Systems (pink stickies)
- Commands (blue stickies)
- Commands initiated by a user (blue stickies annotated with a person)
In the flow above, we’ve captured quite a lot of detail with only a few stickies. We know that a user can input credit card details, an event is generated when they are submitted, and a payment processor interacts with an external payment system.
A simple workshop focused on this business process will likely yield discussions such as:
- What type of information do we need to capture from the user?
- What type of information do we include with the credit card event?
- What are the details of the payment processor and how does it interact with the external system?
There are a few other interesting elements that we can use in our flows:
- Timers (orange stickies with a clock)
- Schedulers (orange stickies with a calendar)
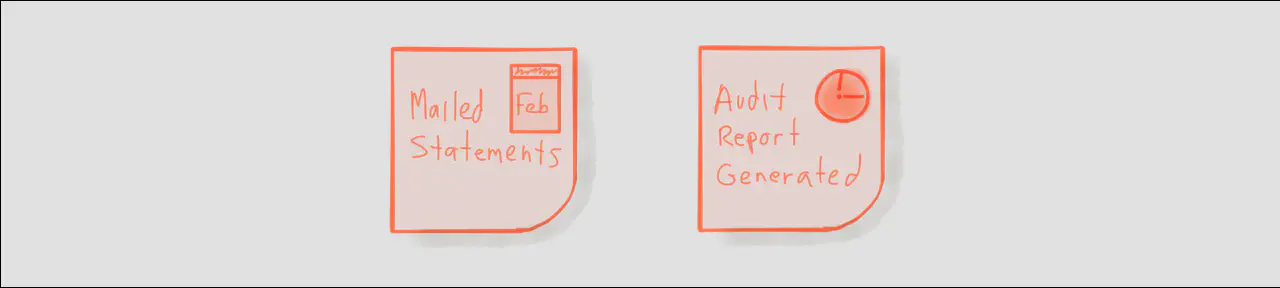
Schedulers and Timers are also very interesting types of events, but they are a often times an implementation-level consideration. We don’t need to delve into this level of detail during a business-focused session. Eventually, developers will need greater precision in their designs, and will consider all aspects of implementation including events that need to be scheduled.
What’s a Command?
Eventually we need to dive deeper and map out exactly how users interact with our system; commands are critical because they often represent user interactions. Adding user interactions to our event flow brings us towards modelling the complete cause-and-effect of our system.
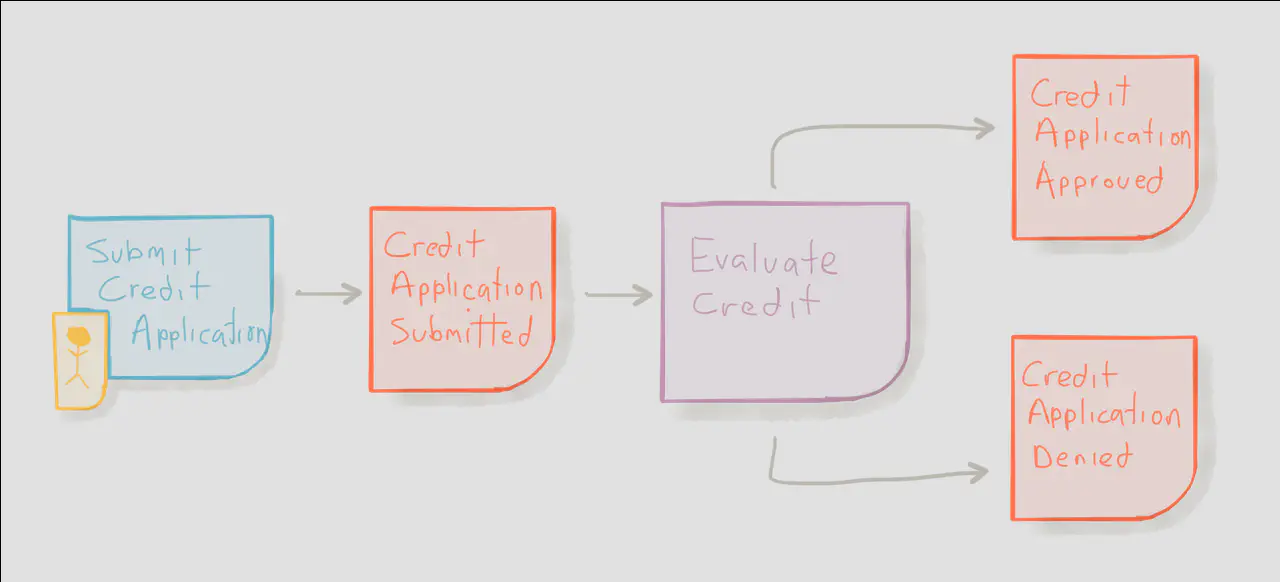
In the above example, we can visualize that a credit application was submitted by a user and eventually causes an approval or rejection decision. As we continue to model this business flow, we’ll eventually make our way to even more detailed elements that help to capture:
- User interface requirements
- Data models
- Etc
Keen observers will also notice that commands are very similar to reactions.The only difference between commands and reactions is that commands are often initiated by users, while reactions are often initiated by events. It’s helpful for your team to agree on how to discuss the nuances of commands and reactions right from the beginning — for example, some teams use reactions purely to document more complex processes, and use commands for both system and user actions. It’s completely acceptable to tailor the way your team uses various elements of event storming to meet your own needs, as long as your team crafts a legend that everyone follows.
For high-level Event Storming, commands, events, and reactions give us enough building blocks to discuss the core of our system. We’ll eventually want to dive deeper into the realm of implementation. Once we get there we’ll need elements that help us model and define the structure of our system.
The most effective way to define structure within an event-driven system is to use the technique of Domain-Driven Design.
Next, we’ll cover the basics on Domain-Driven Design, and how a few key building blocks can help us to put structure around our flows.
Domain-Driven Design
Where an Event Storming session can be used to model business process flows, Domain-Driven Design provides the discipline to turn those flows into a structured system. When we mention system we do not automatically mean code, we simply mean a “system” in the purest sense of the word, whether that system is manual or automated.
Among all approaches to software development, Domain-Driven Design is the only one that focused on language as the key tool for a deep understanding of a given domain’s complexity.
At a high-level, Domain-Driven Design provides structure around events by identifying natural boundaries within an organization and identifying the co-operation required across those boundaries.
Imagine the common scenario in which you attempt to model a business process flow that spans across teams and even departments in a large corporation…
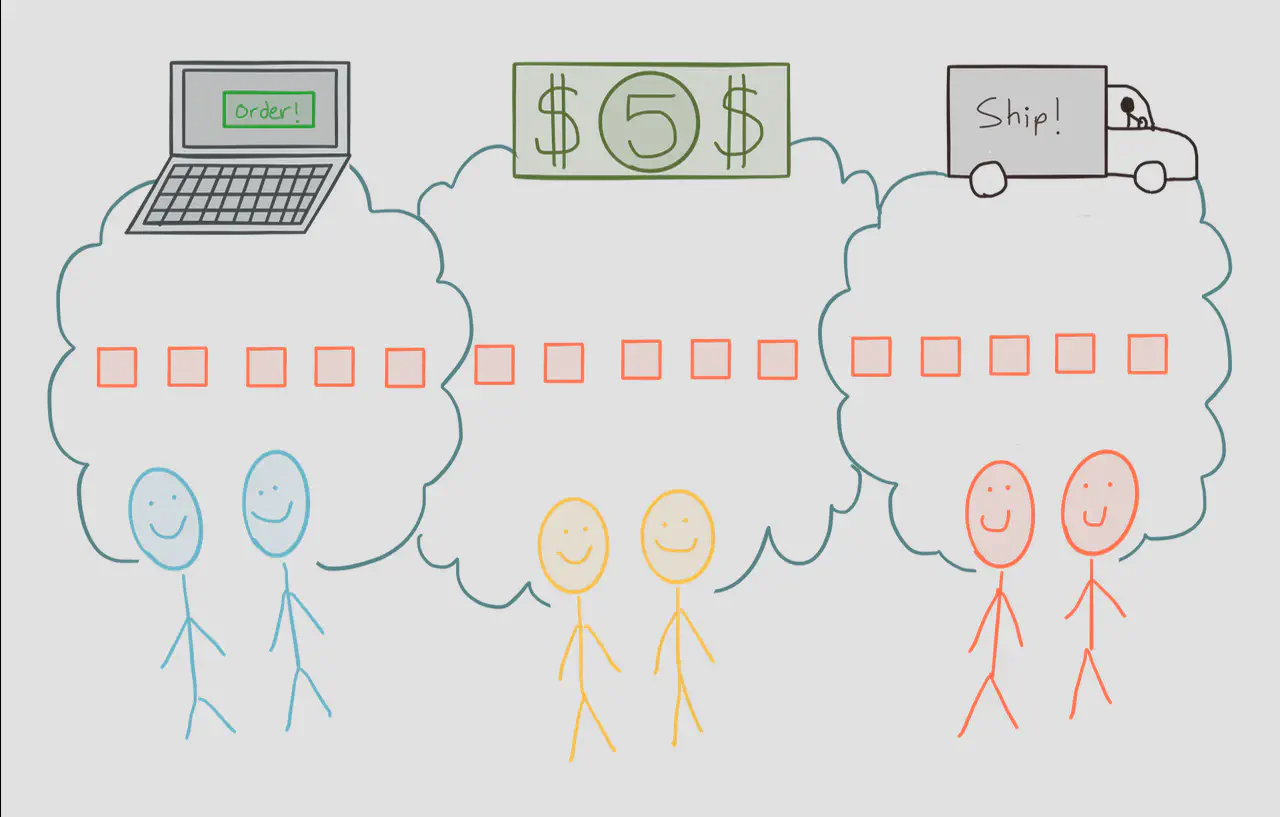
There’s a tremendous coordination cost involved for teams to agree on processes that span organizational boundaries. It’s even more painful when a_single system must be maintained by multiple teams._ This type of impedance is what we must avoid at all costs. Domain-Driven Design gives us some tools that can help us avoid this kind of situation, although no modelling technique is foolproof.
To put structure to our flows, we’ll focus on two core elements of DDD — aggregates and bounded contexts.
What’s an Aggregate?
Aggregates logically group various commands, events, and reactions together.This helps us craft software in a way that fully respects relationships within business processes.
When we get to this level of detail, we can start to think in more specific terms of aggregate events and domain events.
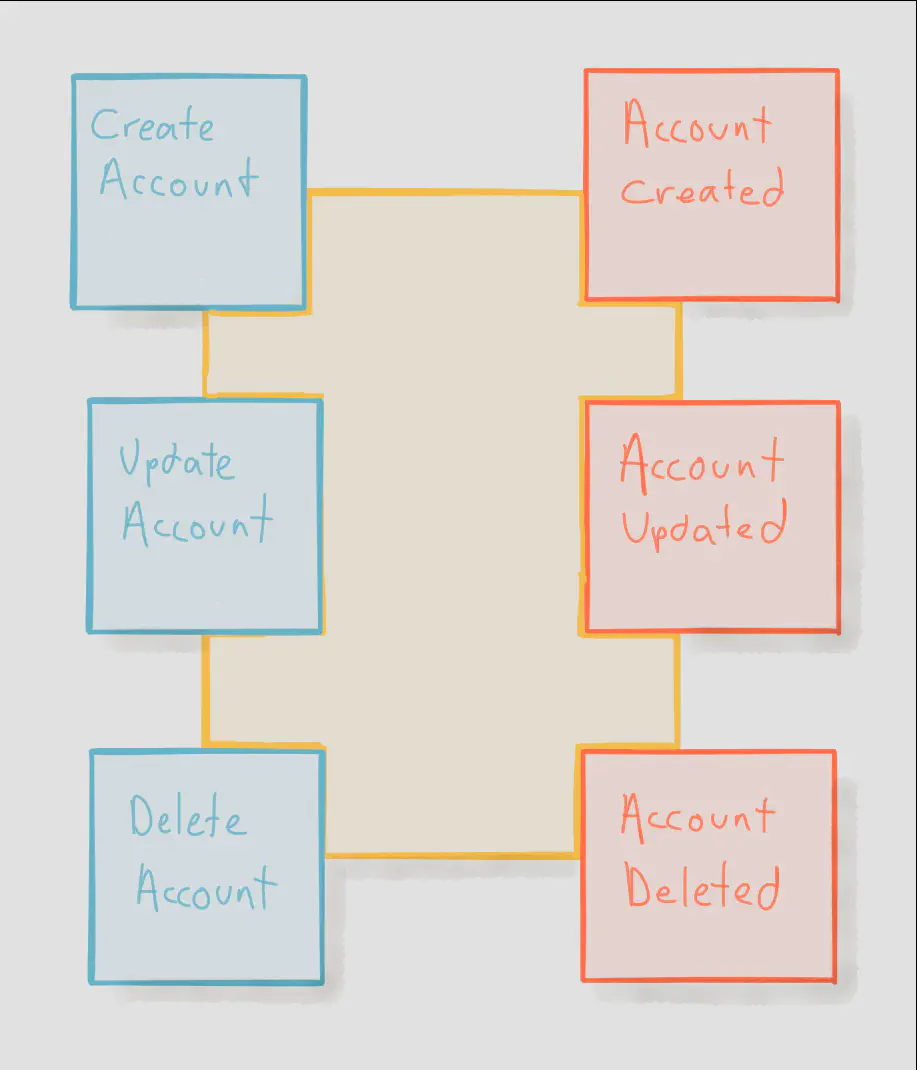
Aggregate events are relevant within the boundary of the aggregate itself, whereas domain events are relevant to the wider system. There are many events that are so specific that leaking them into the wider organization would cause too much confusion, so aggregate boundaries essentially communicate that “these events are only interesting within the aggregate’s boundary — any event emitted outside of this boundary should be interesting to the domain”.
We don’t need to create aggregates until we get deeper into the solution space. Once we start thinking in terms of aggregates, we’re really thinking in terms of implementation — but there’s another reason to begin thinking about aggregates early.
The human brain can only retain so much complexity before it simply runs out of capacity to learn. One of the most harmful aspects of legacy systems is the unbounded nature of the knowledge required before being productive within the system.
What happens if I change a line of code in the shipping module; will it break payments?
Aggregates bring structure to our design by isolating related concerns from one another.
All of the functionality within an aggregate boundary should be easily understood by a single person, including the impact of changes within that boundary.
Aggregates are not critical to leverage during a high-level modelling session focused on business flow, but if you find yourself thinking in terms of solutions, aggregates provide the necessary structure for meaningful implementation discussions.
What’s a Bounded Context?
Bounded contexts are used to create bulkheads within large, complex systems.Like bulkheads in a ship hull that prevents a breach from sinking the entire ship, a bulkhead in a system prevents unnecessary complexity from leaking outside the contextual boundary.
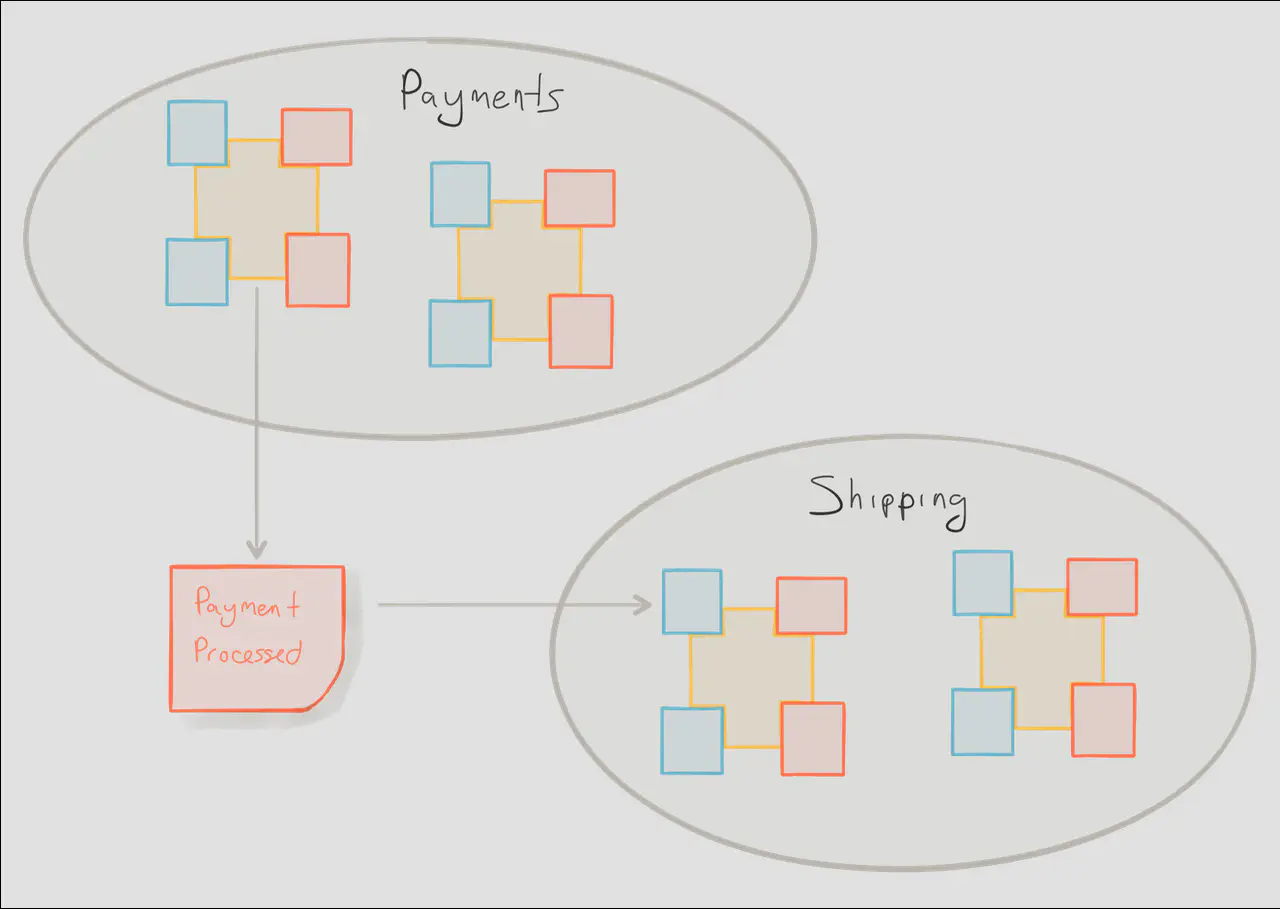
Whereas aggregate boundaries group related behaviours together, bounded contexts group related language, meaning, and culture. For instance,“Confirmation” within a Shipping context may mean something completely different than “Confirmation” within a Payment context. Bounded contexts help to avoid dreaded monsters like “ShippingConfirmation” from escaping their cage and wreaking havoc across the entire organization.
By defining bounded contexts, we can begin to understand how subdomains of the system interact without needing to dive into the guts of code. The Shipping system may be a legacy J2EE app, the Payment system may be a modern system built in Akka, but they speak to each other purely in events.
Conclusion
Event Storming is a collaborative exercise that knows no job titles or hierarchy, it’s only ideas that count — but, in the real-world, decision makers need to feel comfortable moving the exercise forward with action. The _models_are a byproduct of conversations, and it’s those conversations that are the real value. The increase in communication will have ripple effects throughout the organization. Models can be used as actionable blueprints for software development, but they can also be used simply as a tool for enhancing the flow of communication. When blueprints are used to build software, the result is code that reflects the language and structure of the business. Cross-functional teams are then able to talk and reason about the code using the same language and models as the business, ensuring future collaboration is effective and accurate.
I highly recommend the following resources to learn more about Event Storming and Domain-Driven Design:
- Event Storming by Alberto Brandolini is a pre-release book from the creator of Event Storming himself, and is shaping up to be the seminal text on the techniques described in this article.
- Domain-Driven Design Distilled by Vaughn Vernon is the best concise introduction to DDD currently available. I’ve had the pleasure of co-hosting an event storming workshop with Vaughn, and his level of understanding how to model event-driven systems is second-to-none.
- Domain-Driven Design: Tackling Complexity in the Heart of Software by Eric Evans is the seminal text on DDD. It’s not a trivial read, but for software architects looking to dive deep into how to model modern systems, it should be at the top of their reading list.