To understand Reactive — both the programming paradigm and the motivation behind it — it helps to understand the challenges that are faced by developers and companies today compared to the challenges faced only a decade ago.
The two major game changers for developers and companies are:
- Advancements in hardware.
- The Internet.
While “gathering around the campfire to discuss the olden days” is considered to be the lowest form of conversation by some, we need to explore the history of our profession in order to address issues that every developer will soon face.
Why Things are Different Now
There’s a wealth of knowledge at our disposal gained over decades of research in computing. Reactive programming is an attempt to capture that knowledge in order to apply it to a new generation of software.
1999
When I began to learn Java in 1999 while interning at the Canadian Imperial Bank of Commerce:
- The Internet had 280 million users.
- J2EE was still a dream in the hearts and minds of Sun Microsystems.
- Online banking was in its infancy — 5 years old, give or take.
Even back in 1999 I began to encounter problems of concurrency. The solutions involved threads and locks, complicated things to get right even for experienced developers. The main selling feature of Java was the ability to “write once, run anywhere”, but anywhere was in the context of which operating system the JVM was installed on, not concepts like the cloud or the massive number of concurrent connections that we’re designing for in the age of the Internet of Things.
2005
2005 wasn’t very long ago, but the world of computing and the Internet looked quite a bit different. J2EE, SOA, and XML were the hotness. Ruby on Rails was born as a challenge to the painful container-based deployment model of J2EE.
A few other fun factoids:
- The Internet had 1 billion users.
- Facebook had 5.5 million users.
- YouTube was a newborn (February, 2005).
- Twitter wasn’t alive yet (2006).
- Netflix had yet to introduce video streaming (2007).
2014
In 2014 — at the time of this writing — there are approximately 2,950,000,000 (2.95 billion) Internet users according to Internet Live Stats. China alone has 640 million Internet users. The United States has 280 million.
Two of the most popular websites today:
- Facebook — 1.3 billion users.
- Twitter — 270 million users.
Times have changed. A single website may now handle as much traffic as the entire Internet did less than a decade ago.
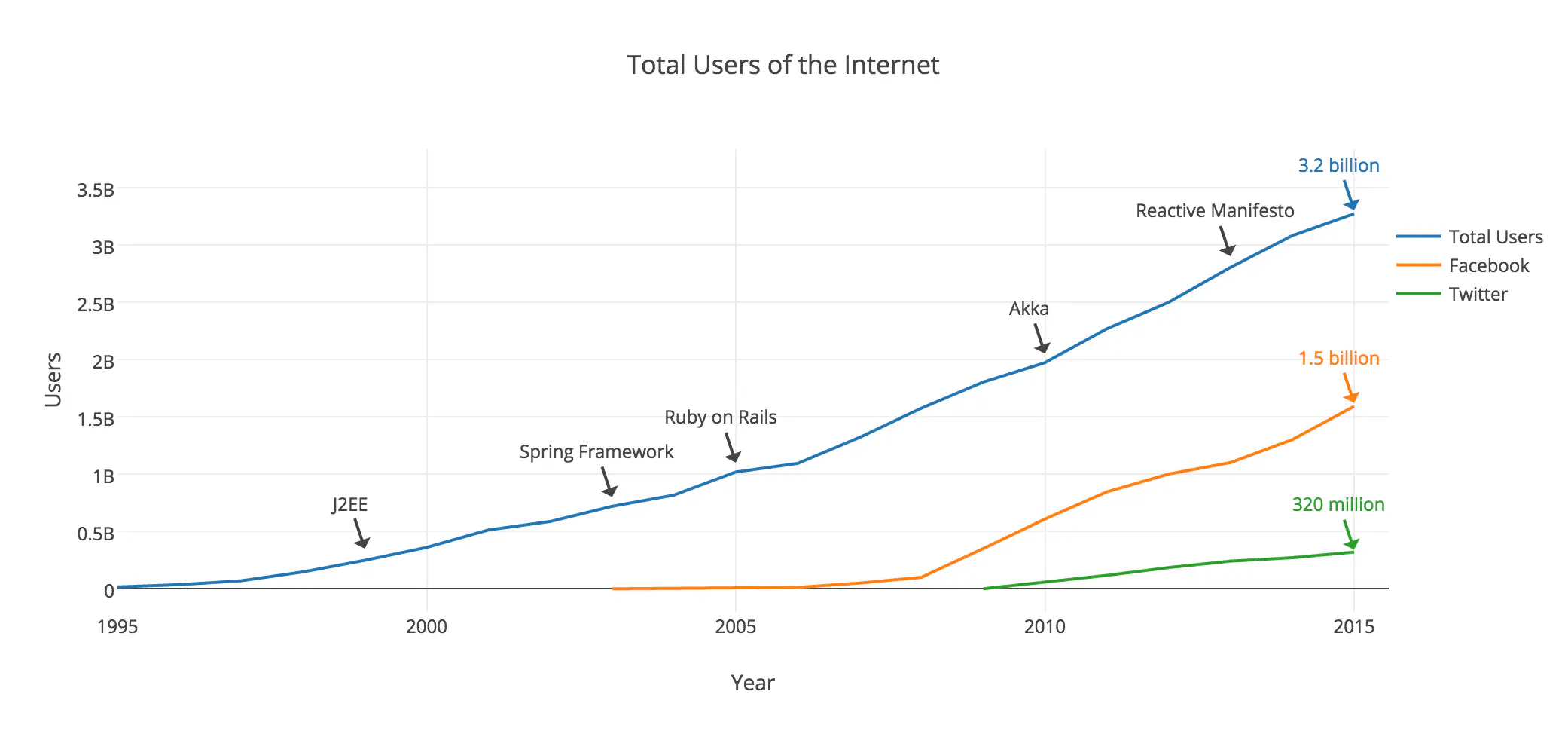
Total users of the Internet, Facebook, and Twitter, from 1995 to 2015.
It’s easy to see that we’re facing issues of scale, expectations, and importance of software in our day to day lives. It’s also easy to see that some paradigms of the past may not scale to the present, and certainly not to the future.
The Four Reactive Principles: Responsive, Resilient, Scalable, Message-Driven
Reactive applications are built on four guiding principles.
The core building blocks of Reactive applications.
- A responsive application is the goal.
- A responsive application is both scalable and resilient. Responsiveness is impossible to achieve without both scalability and resilience.
- A message-driven architecture is the foundation of scalable, resilient, and ultimately responsive systems.
Let’s explore each principle at a high-level in order to understand why all of them must be applied together in order to develop quality software in a modern context.
Responsive (The Goal)
What do we mean when we say that an application is responsive?
A responsive system is quick to react to all users — under blue skies and grey skies — in order to ensure a consistently positive user experience.
Quickness and a positive user experience under various conditions, such as failure of an external system or a spike of traffic, depends on the two traits of a Reactive application: resilience and scalability. A message-driven architecture provides the overall foundation for a responsive system.
Why is a message-driven architecture so important for responsiveness?
The world is asynchronous. Here’s an example: you’re about to brew a pot of coffee, but you realize you’re out of cream and sugar.
One possible approach:
- Begin to brew a pot of coffee.
- Go to the store while the coffee is brewing.
- Buy cream and sugar.
- Return home.
- Drink coffee immediately.
- Enjoy life.
Another possible approach:
- Go to the store.
- Buy cream and sugar.
- Return home.
- Start brewing a pot of coffee.
- Impatiently watch the pot of coffee as it brews.
- Experience caffeine withdrawal.
- Crash.
As you can clearly see, a message-driven architecture provides you with an asynchronous boundary that decouples you from time and space. We’ll continue to explore the asynchronous boundary concept throughout the rest of this post.
Consistency at Walmart Canada
Before joining Typesafe, I was the technical lead of the Play and Scala team that built Walmart Canada’s new eCommerce platform.
Our goal was the consistency of a positive user experience, regardless of:
- What type of physical device was used to browse walmart.ca, whether it be a desktop, tablet, or mobile device.
- Current peak traffic, whether it be a spike or sustained.
- A major infrastructure failure such as the loss of an entire data center.
Response times and overall user experience had to remain consistent regardless of the above scenarios. Consistency is fundamentally important for your website to deliver, considering that today your website is your brand. A poor experience is not forgotten or ignored simply because the experience happened online rather than in a brick and mortar store.
Responsive retail at Gilt
Consistency in the eCommerce domain doesn’t happen by accident. Case in point is Gilt, a flash sale site that experiences a major spike of traffic every day when they announce the daily sale items at noon.
Let’s consider the user experience of a flash sale site. If you browse Gilt at 11:58AM and again at 12:01PM, you expect the same positive experience between your two visits despite the fact that Gilt is being swarmed with traffic after noon.
Gilt delivers that consistently positive, responsive experience, and achieved it by going Reactive. Learn more about Gilt’s migration to a Scala-based microservices architecture in this ReadWrite interview with Eric Bowman of Gilt.
Resilient (First Pillar)
Most applications are designed and developed for blue skies, but things can and do go wrong. It seems like every few days there’s another report of a major application failure, or another co-ordinated breach of systems by hackers that results in downtime, data loss, and damaged reputations.
A resilient system applies proper design and architecture principles in order to ensure responsiveness under grey skies as well as blue.
While Java and the JVM were all about seamlessly deploying a single application to multiple operating systems, the interconnected applications of the twenty-teens (201x) are all about application-level composition, connectivity, and security.
Applications are now composed from a number of other applications, integrated via web services and other network protocols. An application built today may depend on a large number of external services — 10, 20, or even more — outside of its own trusted firewall. It may also serve a large number of external clients, both people and other systems.
With this integration complexity in mind, how many developers:
- Analyze and model all external dependencies?
- Document ideal response times of each service that’s integrated with, conducting performance tests — both peak and endurance — to sanity-check the initial expectations?
- Codify all performance, failure, and other non-functional requirement expectations to be included as part of core application logic?
- Analyze and test against all failure scenarios of each service?
- Analyze the security of external dependencies, recognizing that integrating with an external system creates new vulnerabilities?
Resiliency is one of the weakest links of even the most sophisticated application, but resiliency as an afterthought will soon end. Modern applications must be resilient at their core in order to stay responsive under a variety of real-world, less than ideal conditions. Performance, endurance, and security are all facets of resiliency. Your applications must be resilient on all levels, not just a few.
Message-Driven Resiliency
The beauty of building on top of a message-driven core is that you naturally get a number of valuable building blocks to work with.
Isolation is needed for a system to self-heal. When isolation is in place, we can separate different types of work based on a number of factors, like the risk of failure, performance characteristics, CPU and memory usage, and so on. Failure in one isolated component won’t impact the responsiveness of the overall system, while also giving the failing component a chance to heal.
Location transparency gives us the ability to interact with different processes on different cluster nodes just like we do in-process on the same VM.
A dedicated separate error channel allows us to redirect an error signal somewhere else rather than just throwing it back in the caller’s face.
These factors help us towards incorporating robust error handling and fault tolerance into our applications. This is demonstrated in action through implementations like Akka’s supervisor hierarchies.
The core building blocks provided by a message-driven architecture contributes to resiliency, which in turn contributes to responsiveness — not only under blue skies, but under a variety of less-than-ideal, real-world conditions.
The 440 Million Dollar Resiliency Mistake
Consider the software glitch experienced by Knight Capital Group in 2012. During a software upgrade, another dormant, integrated application was inadvertently fired up and began amplifying trading volumes.
What happened over the next 45 minutes was a nightmare scenario.
Knight’s automated trading system flooded NASDAQ with erroneous trades and put the company into billions of dollars worth of unintended positions. It cost the company 440 million dollars to reverse. During the glitch Knight couldn’t stop the deluge of trades that flooded NASDAQ, so NASDAQ had to pull the plug on Knight. Knight’s stock slid 63% in a single day and they barely survived as a company, only hanging in there after the stock regained some of its value and after a subsequent takeover by investors.
Knight’s systems were performant, but they were not resilient. Performance without resilience can amplify problems as Knight discovered. Knight didn’t even have a kill-switch mechanism in place to pull the plug on their system should a catastrophic bug occur, so under grey skies their automated trading system depleted the entire capital reserves of the company within 45 minutes.
This is the definition of designing and developing for blue skies. Now that software is such a core component of our personal lives and our businesses, a grey sky scenario can be very costly if it is not expected and designed for, even within an hour.
Scalable (Second Pillar)
Resiliency and scalability go hand-in-hand when creating consistently responsive applications.
A scalable system is easily upgraded on demand in order to ensure responsiveness under various load conditions.
Anyone who sells things online understands a simple fact: your largest spikes of traffic are when you sell the most stuff. For the most part — unless the spike is a purposeful cyberattack — experiencing a large burst of traffic means you’re doing something right. During a spike of traffic people want to give you money.
So how do you handle a spike — or a steady but significant increase — of traffic?
Choose your paradigm first, and then choose the languages and toolkits that embrace that paradigm second. All too often developers simply pick a language and framework… ”because”. Once tooling decisions are made they’re difficult to reverse, so approach those decisions as you would with any major investment. If you make technical selection decisions based on principles and analysis you’re already well ahead of the pack.
Thread-based Limitations to Concurrency
One of the most critical aspects of technical selection decisions is the concurrency model of a framework. At a high-level, two distinct concurrency models exist:
- Traditional thread-based concurrency based on a call stack and shared memory.
- Message-driven concurrency.
Some popular MVC frameworks like Rails are thread-based. Other typical characteristics of these frameworks include:
- Shared mutable state.
- A thread per request.
- Concurrent access to mutable state — variables and object-instances — managed with locks and other complicated synchronization constructs.
Combine those traits with a dynamically typed, interpreted language like Ruby and you can quickly reach the upper bounds of performance and scalability. You can say the same for any language that is essentially, at its core, a scripting language.
Scaling Out or Up?
Let’s consider the different ways to scale an application.
Scaling up involves maximizing the resources of a single CPU/server, often requiring the purchase powerful, exotic, expensive hardware.
Scaling out involves distributing computation across a cluster of cheap commodity hardware (e.g, the cloud) which is cost efficient, but very difficult to accomplish when your system is based around the concepts of time and space. As we mentioned earlier, a message-driven architecture provides the asynchronous boundary needed to decouple from time and space, providing the ability to easily scale out on demand, also known as elasticity. While scaling up is about the efficient use of resources already available, elasticity is about adding new resources to your system on demand as the needs of your system change. The ability to scale out, on demand is the ultimate scalability goal of a Reactive application.
Reactive applications are difficult to build with thread-based frameworks because of how difficult it is to scale out an application based on shared mutable state, threads, and locks. Not only do developers need to be able to take advantage of multiple cores on a single machine, at a certain point developers need to take advantage of clusters of machines. Shared mutable state also makes it difficult, though not impossible, to scale up. Anyone who has attempted to work with the same shared mutable state in two different threads understands what a complicated process ensuring thread safety is, and also understands the performance penalties associated with over-engineering for thread safety.
Message-Driven (The Foundation)
A message-driven architecture is the foundation of Reactive applications. A message-driven application may be event-driven, actor-based, or a combination of the two.
An event-driven system is based on events which are monitored by zero or more observers. This is different than imperative programming because the caller doesn’t need to block waiting for a response from the invoked routine. Events are not directed to a specific address, but rather watched (or listened) for, which has some implications that we’ll discuss further.
Actor-based concurrency is an extension of the message-passing architecture, where messages are directed to a recipient, which happens to be an actor. Messages may cross thread boundaries or be passed to another actor’s mailbox on a different physical server. This enables elasticity — scaling out on demand — as actors can be distributed across the network, yet still communicate with each other as if they were all sharing the same JVM.
The main difference between messages and events is that messages are_directed_ while events happen. Messages have a clear destination while events may be observed by zero or more (0-N) observers.
Let’s explore event-driven and actor-based concurrency in a little more detail.
Event-Driven Concurrency
Typical applications are developed in imperative style — a sequential order of operations — and based around a call stack. The main function of the call stack is to keep track of the caller of a given routine, execute the invoked routine while blocking the caller in the process, and returning control to the caller with a return value (or nothing at all).
Superficially, event-driven applications are not focused on the call stack, but rather on triggering events. Events may be encoded as messages that are placed in a queue that is monitored by zero or more observers. The big difference between event-driven and imperative style is that the caller does not block and hold onto a thread while waiting for a response. The event-loop itself may be single threaded, but concurrency is still achieved while invoked routines go about their business (and potentially block on IO themselves) while allowing the (sometimes single) threaded event-loop to process incoming requests. Instead of blocking on a request unless completely processed, the caller’s identity is passed along with the body of the request message so that — if the invoked routine chooses to do so — the caller can be called back with a response.
The main consequence of choosing an event-driven architecture is that they can suffer from a phenomenon called callback hell — see http://callbackhell.com for examples. Callback hell occurs because the recipients of messages are anonymous callbacks instead of addressable recipients. Common solutions to callback hell focus purely on the syntactic aspect — aka, the Pyramid of Doom — while neglecting the difficulties that arise in reasoning about and debugging the sequence of events expressed in the code.
Actor-based Concurrency
Actor-based applications revolve around asynchronous message passing between multiple actors.
An actor is a construct with the following properties:
- A mailbox for receiving messages.
- The actor’s logic, which relies on pattern matching to determine how to handle each type of message it receives.
- Isolated state — rather than shared state — for storing context between requests.
Like event-driven concurrency, actor-based concurrency eschews the call stack in favour of lightweight message passing. Actors can pass messages back and forth, or even pass messages to themselves; an actor can pass a message to itself in order to finish processing a long-running request after it services other messages in its queue first. A huge benefit of actor-based concurrency is that in addition to the benefits gained by an event-driven architecture, scaling computation out across network boundaries is even easier, and callback-hell is avoided because messages are directed to actors. This is a powerful concept that makes it easy to build hyper-scalable applications that are also easy to design, build, and maintain. Rather than thinking about time and space, or deeply nested callbacks, you only need to think about how messages flow between actors.
Another major benefit of an actor-based architecture is the loose coupling of components. The caller doesn’t block a thread waiting for a response, therefore the caller can quickly move onto other work. The invoked routine, encapsulated by an actor, only needs to call the caller back if necessary. This opens up many possibilities, like distributing routines across a cluster of machines, because the call stack doesn’t couple applications to a single space in memory and the actor-model makes the deployment topology an abstracted away configuration concern rather than a programming concern.
Akka is an actor-based toolkit and runtime — part of the Typesafe Reactive Platform — for building highly concurrent, distributed, and fault tolerant actor-based applications on the JVM. Akka has a number of other incredible features for building Reactive applications, like supervisor hierarchies for resilience and distributed workers for scalability. A deep dive into Akka is beyond the scope of this article, but I highly recommend visiting the Let it Crash blog for more Akka related content.
I also highly recommend reading Benjamin Erb’s Diploma Thesis, Concurrent Programming for Scalable Web Architectures, which was used as a source of information for part of this section.
Conclusion
All of the above scratches the surface of developing applications today, and leads to why Reactive programming isn’t just another trend but rather _the_paradigm for modern software developers to learn. Regardless of the language or toolkit you choose, putting scalability and resilience first in order to achieve responsiveness is the only way to meet the expectations of users. This will only get more important with each passing year.