The Play framework is a web framework for the JVM that breaks away from the Servlet Specification. Play embraces a fully reactive programming model through the use of futures for asynchronous programming, work stealing for maximizing available threads, and Akka for distribution of work.
Not only does Play have some extreme advantages over servlet-based web frameworks, it also has full support for two of the most popular languages on the JVM, Java and Scala.
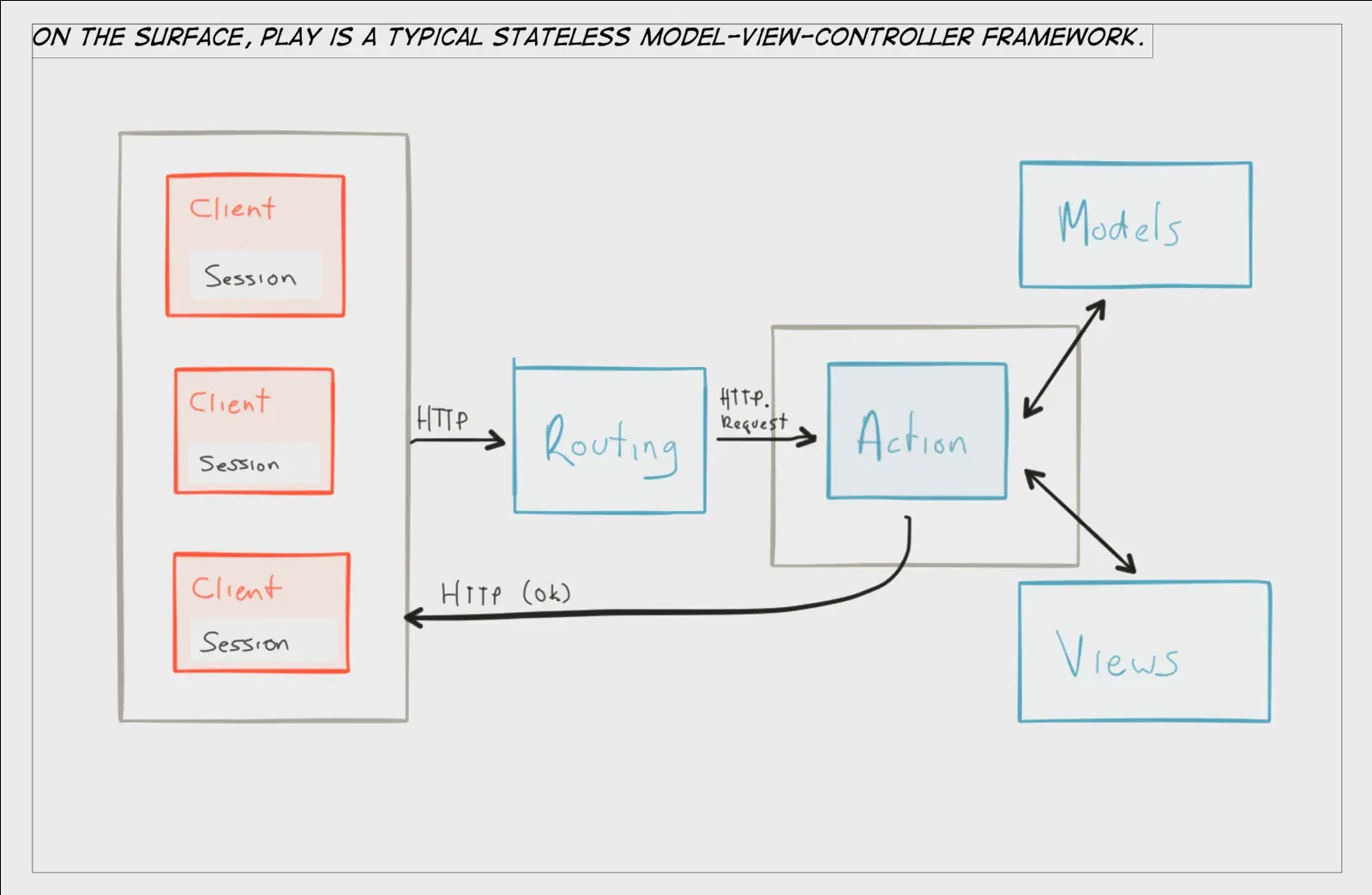
Play is anything but your typical MVC framework. Play is a performance beast capable of powering some of the most resource intensive sites on the internet, like LinkedIn and Walmart Canada. But with great power comes responsibility. The most important factor in being successful with Play is how well a development team understands Play’s concurrency model.
I wrote the first line of code on the current Walmart Canada platform, and after that I worked at Lightbend as Enterprise Architect from 2014 to 2016. Over the years, I’ve seen many implementations of Play — most were successful, some were not.
Unsuccessful efforts with Play usually boil down to one thing — a team not invested in learning about the reactive paradigm, especially around concurrency and distribution.
I feel that the key strength of Play is also one of its key weaknesses; superficially it looks very similar to any other typical MVC framework, while under the hood it’s a totally different beast. This traps some fast-moving teams into misunderstanding Play and failing in their efforts due to poorly written legacy code and equally poor tuning for production environments.
With that in mind, this is not a comprehensive introduction to Play, but rather a dive into the differences between Play and traditional web frameworks. I hope the content here will point new Play developers in the right direction when thinking about not only how to build a Play application, but how to build an efficient web-facing distributed system using Play’s unique and powerful approach to scaling up.
A Concurrency Story
Imagine we have a warehouse with a small team of shippers, and all of the workers are unionized. Their job is to pull boxes from a queue, follow the instructions to get the items for the order, pack the boxes, and ship the boxes.
- A task is added to a box
- The box placed on a queue
- A worker picks a box from a queue
- The worker follows the task instructions and acquires items from the store
- The worker places the items in the box and seals the box
- The worker ships the box
- The worker picks another box from the queue
On top of their day-to-day process, a few rules in their contract limit overall productivity of the warehouse, but ensure a very strong work/life balance for the workers.
- A worker is assigned to a specific queue; they cannot pick boxes from another queue
- Once a box is picked, it must be packed and shipped before the worker picks another box
- A worker can only work on one box at a time
Some of the clauses in this contract will make life easy for the factory managers and workers, but will certainly cause delays for customers.
Inefficient Scheduling
If a worker is blocked while preparing the box for shipping, the rules in the contract make it very inefficient for them to continue being productive.
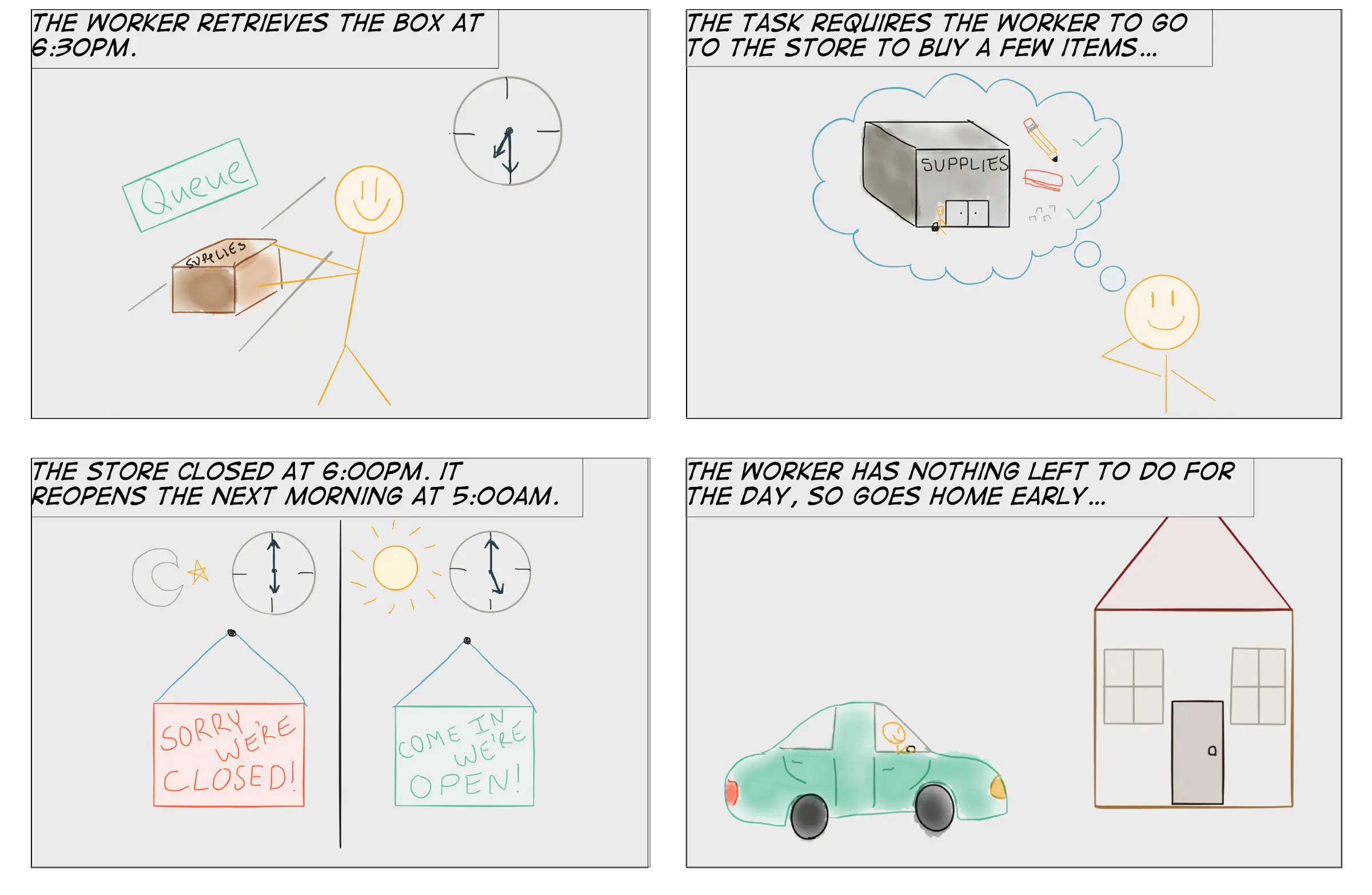
The worker had no choice but to go home or return to the factory and be bored for the rest of their shift. Remember, they can only work on one box at a time and must work on the same box until they ship it!
Not only does the worker lose the rest of their day, but they aren’t even back in the factory until later in the morning the next day. They’ve lost productive time on day 1, and the package is shipped later than it needs to be on day 2. What a major waste!
Scheduling Improvements
There are obvious problems with this hypothetical supply chain, like the fact that workers don’t have a warehouse to acquire items from but rather go to the store for items.
Let’s suspend disbelief for a few moments while we look into the coordination issues causing such a big waste in our example above.
Rather than stick to the original union contract, let’s renegotiate the contract to take the morning shift into account.
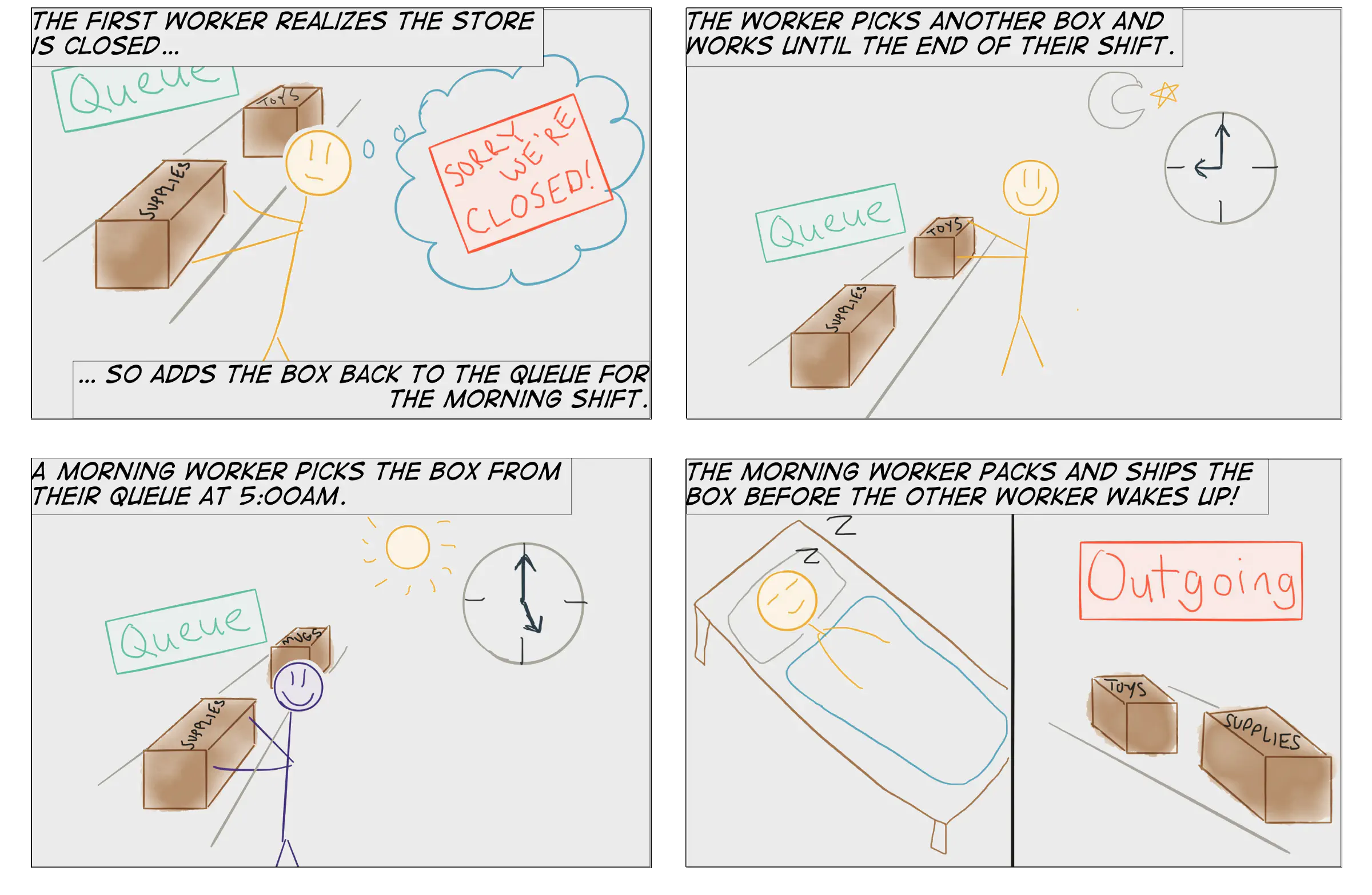
In this scenario, we’ve rescued a few hours of productive work from the first worker, and the second worker was able to get the box shipped a few hours earlier than would have happened with the first inefficient scheduling algorithm.
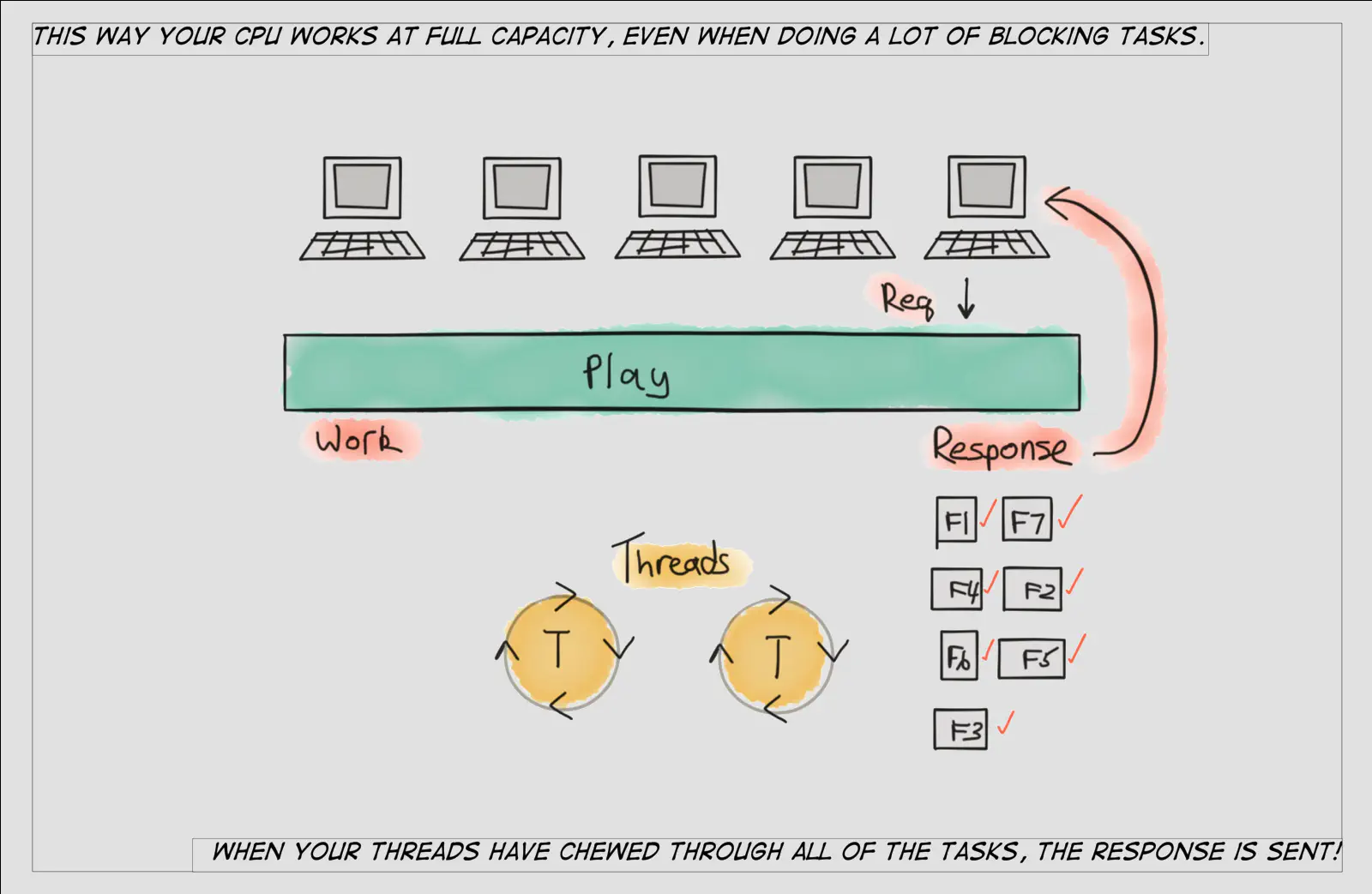
This is more or less how work stealing functions in Java. Work stealing is a solution for coordination and scheduling inefficiencies with plain old thread pools. Work stealing is a huge improvement when you consider that scheduling in most servlet-based MVC frameworks involves nothing more elegant than a thread grabbing requests from a FIFO queue and spinning on the request — even when blocked — until it has enough data to send a response.
It’s the difference in elegance between painting with an artist’s airbrush and painting with a sledgehammer dipped in paint.
Concurrency in Java
Play concurrency is built on top of Java concurrency, so it’s important to understand the basics of Java concurrency before you start production tuning Play applications.
ForkJoin
Under the covers of Play, work stealing is implemented with the ForkJoin Framework (JSR-166). ForkJoin was first added to Java 7 and then refined in Java 8, making it more efficient for Java developers to write concurrent/parallel code and avoid the complexities of locks, monitors, and synchronization.
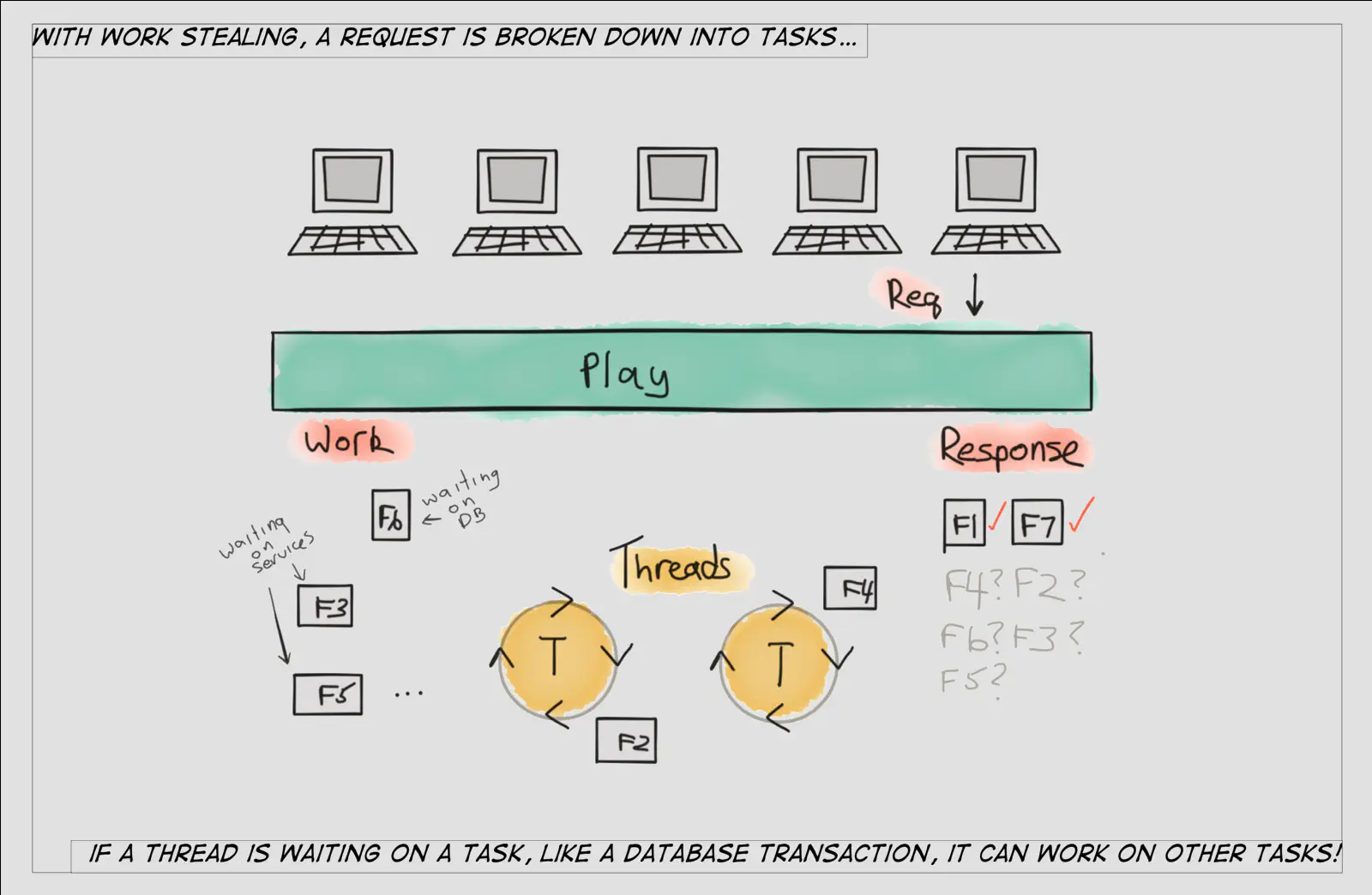
Work stealing can be considered a subset of scheduling, and ForkJoin implements its own work stealing technique when scheduling tasks that can be broadly described as follows:
The fork/join framework is distinct because it uses a work-stealing algorithm. Worker threads that run out of things to do can steal tasks from other threads that are still busy. — The Java™ Tutorials
The parallelism building blocks in ForkJoin are:
ForkJoinPool— An instance of this class is used to run all of your fork-join tasksRecursiveTask— Run a subclass of this in a pool and have it return a resultRecursiveAction— Run a subclass of this in a pool but without returning a resultForkJoinTask— Superclass ofRecursiveTaskandRecursiveAction; fork and join are methods defined in this class
Traditionally, web frameworks assign a new request to a thread and the thread processes the request until it sends a response back to the client. This is inefficient for web systems because servicing a typical request requires blocking the thread for a number of tasks like database transactions, external web service calls, etc. Heritage web frameworks were not built for the sheer volume of interactions that modern web-facing systems demand, like executing tens (or hundreds!) of back-end transactions to service a single request.
With work stealing, rather than hog a thread even while it’s blocked (e.g, waiting for a response from a database), we have a much more sophisticated way to schedule the tasks involved in building out a response that takes into account that many of the tasks involve waiting around rather than productive work.
Concurrency in Play
Now that we have a general understanding of what ForkJoin is, let’s dive into how Play builds on top of ForkJoin to implement its own concurrency model.
Execution contexts
An ExecutionContext is the main concurrency abstraction in Play that represents either a thread pool or ForkJoin pool.
In Java this is called Executor. Keep in mind that Play itself is written in Scala, so when you’re configuring concurrency in Play you’ll use the ExecutionContext term.
This is one area in the Lightbend platform where Scala bleeds into the API for Java developers. It’s not an issue as long as you understand why and where the naming conventions are different. Ultimately, understand that Scala is the underpinning of all frameworks in the Lightbend platform, so Scala will inevitably bleed into the Java APIs in small ways.
Futures
A Future[T] in Scala — or CompletionStage<T> in Java — can be considered a box that represents a task to be completed and an eventual value.
The tasks can be considered the operations that gather items for our box before shipping it to the receiver.
In Play, the T represents the type of item that will be placed inside the box. The tasks would be each individual step defined within a Play action. Instead of going to a store, a task would involve going to a database.
Actions
The core of the developer experience in Play are actions, which are functions that are executed when an incoming request is routed to that action based on URI matching. An action can be defined as synchronous or asynchronous.
Because Play is built on top of Scala, a hybrid object/functional programming language, actions themselves are simply anonymous functions.
Actions have a return type as follows:
- Scala —
Future[HttpResponse](asynchronous) - Scala —
HttpResponse(synchronous) - Java —
CompletionStage<Result>(asynchronous) - Java —
Result(synchronous)
As you can see, without futures you simply have synchronous actions. When you combine actions with futures, you have asynchronous actions.
Scala
The following Scala action is synchronous:
def index = Action { implicit request =>
Ok(...)
}
The following Scala action is asynchronous:
def index = Action.async { implicit request =>
Future(Ok(...))
}
All that separates a synchronous action from an asynchronous action in Play is .async. One of the biggest mistakes I find during Play code reviews is a fundamental misunderstanding of what async means, and without the proper use of .async, Play can suffer from worse performance than a synchronous, servlet-based framework. It’s simply not tuned to allocate a single thread for every single request/response.
Java
In Java, an asynchronous action has a type of CompletionStage<Result>. In this Java example we process a simple form from the client and grab the items of a shopping cart asynchronously:
public CompletionStage<Result> index() {
Form<CheckoutForm> checkoutForm = formFactory.form(CheckoutForm.class);
CompletionStage<Cart> cartFuture = CompletableFuture.supplyAsync(() -> cartService.getCartForUser(), ec.current());
return cartFuture.thenApply(cart -> ok(index.render(cart, checkoutForm)));
}
You’ll notice that the method we call to get the client’s shopping cart is also asynchronous. Within an action, if all of our dependent method calls return CompletionStage<T>, we can compose the entire action to be asynchronous all the way down.
Putting the Pieces Together
Let’s review our original concurrency example and consider the following:
- The box represents the instance of
Future[T](in Scala) orCompletionStage<T>(in Java) - The tracking number represents the reference to the future
- The task represents the lambda code that produces the result
- Item(s) placed inside the box represents the result
The syntactic difference of implementing efficient concurrency and scheduling is subtle, just like the inefficiencies in our anecdotal example.
Modern web applications rely on many blocking calls to produce results, such as making requests from external web services and databases.
Wherever possible it’s best to eliminate blocking calls altogether, but blocking is not the enemy — synchronous blocking is the enemy.
The four modes of concurrency, from best to worse, are:
- Asynchronous and non-blocking (excellent!)
- Asynchronous and blocking (acceptable)
- Synchronous and non-blocking (meh)
- Synchronous and blocking (awful!)
Conclusion
Traditional web frameworks were simply not built for the age of API-first integration. Today, web applications are composed of other web applications which are composed of other web applications. If we look at a typical Play action, it makes calls to caches, databases, web services, identity services, secret stores, and the list goes on. Allocating a single thread for all of that work is completely inefficient given how limited and precious threads are.
Using ForkJoin, on a machine with 48 cores the Akka team was able to saturate those cores with 20 million messages per second. In comparison, using thread pools, they were unable to push more than 2 million messages per second.
Ultimately, getting the most out of Play requires an understanding of how it implements concurrency. Once you do, the benefits of a properly tuned Play application are immense!